数据仓库的演进 Lambda与Kappa架构解析及其数据处理与存储支持服务
在当今大数据时代,数据仓库作为企业数据资产的核心载体,其数据处理架构的选型直接关系到数据分析的实时性、准确性与系统复杂度。Lambda架构和Kappa架构作为两种主流的大规模数据处理范式,为构建高效、可靠的数据仓库提供了不同的设计思路。强大的数据处理与存储支持服务是这些架构得以落地的关键保障。
一、 Lambda架构:批流结合的经典范式
Lambda架构由Nathan Marz提出,其核心思想是通过并行处理批处理层(Batch Layer)和速度层(Speed Layer),并最终在服务层(Serving Layer)进行合并,以平衡延迟、容错和可扩展性。
- 批处理层:负责处理全量历史数据,通常采用Hadoop MapReduce、Apache Spark等计算引擎,以高延迟为代价,确保数据的准确性和完整性。处理结果存储于如HBase、Cassandra或专用OLAP数据库(如ClickHouse、Druid)中,形成批处理视图。
- 速度层:负责处理实时流入的新数据,采用如Apache Storm、Flink、Spark Streaming等流处理引擎,以低延迟生成近实时的增量视图。
- 服务层:合并批处理视图与速度层视图,对外提供统一的数据查询服务。当用户查询时,服务层将两者的结果进行合并,从而得到既包含完整历史又包含最新数据的答案。
Lambda架构的优势在于其容错性高、可扩展性强,并且通过批处理层保证了数据的最终准确性。但其缺点也显而易见:系统复杂,需要维护两套独立的代码逻辑和处理流水线,且需要在服务层处理复杂的合并逻辑。
二、 Kappa架构:简化设计的流处理优先范式
为简化Lambda架构的复杂性,Jay Kreps提出了Kappa架构。其核心思想是:一切皆流。它移除了专门的批处理层,只保留一个流处理层,通过一个可重播的、持久化的消息日志(如Apache Kafka)来存储所有输入数据。
- 统一流处理层:所有数据处理,无论是历史数据还是实时数据,都通过同一个流处理引擎(如Apache Flink)来完成。当需要重新计算全量数据或修复逻辑时,只需从消息日志的起点重新消费数据并执行新的处理逻辑即可。
- 可重播的消息日志:这是Kappa架构的基石。Kafka等系统不仅作为实时数据管道,更作为数据的永久存储源,允许任何时间点启动新的流处理作业进行全量回溯计算。
- 服务层:与Lambda架构类似,处理后的结果被输出到专用的查询数据库或索引中,供下游应用使用。
Kappa架构极大地简化了系统,只需维护一套代码,避免了批流合并的复杂性。它对实时性要求高的场景尤其友好。其挑战在于:对消息日志的存储容量和回溯性能要求极高;进行全量重计算时资源消耗大、耗时较长;对于某些复杂的、周期性的批处理分析任务可能并非最优。
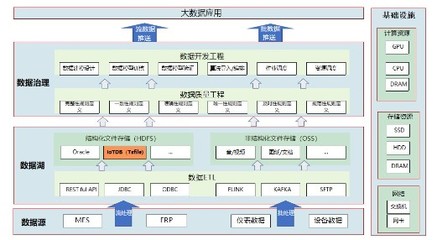
三、 数据处理与存储支持服务
无论是Lambda还是Kappa架构,其高效运行都离不开底层强大的数据处理与存储服务生态的支持。
- 计算引擎服务:
- 批处理:云服务商提供的托管Hadoop/Spark服务(如AWS EMR, Azure HDInsight,阿里云EMR)。
- 流处理:托管Flink/Kafka Streams服务(如AWS Managed Streaming for Kafka,Ververica Platform,阿里云实时计算Flink版)。
- 消息队列与日志服务:作为数据管道和Kappa架构的“存储”,如AWS Kinesis,Azure Event Hubs,以及云托管的Apache Kafka服务,提供了高吞吐、持久化、可重播的数据流支持。
- 存储服务:
- 原始数据湖存储:低成本、高扩展的对象存储服务(如AWS S3,Azure Blob Storage,阿里云OSS),用于存储原始日志和批处理层的原始数据。
- OLAP与分析型数据库:用于服务层,提供低延迟、高并发的查询能力,如云原生的Snowflake、BigQuery,或托管的ClickHouse、Druid、StarRocks服务。
- NoSQL与键值存储:用于存储中间结果或速度层视图,如AWS DynamoDB,Azure Cosmos DB,HBase服务。
- 编排与调度服务:如Apache Airflow的托管服务(如Google Cloud Composer,AWS MWAA),用于协调复杂的批处理工作流和数据处理任务。
四、 架构选型与未来趋势
选择Lambda还是Kappa,取决于业务场景:
- 选择Lambda:当业务对数据准确性要求极高,且存在大量复杂的、周期性的批处理分析任务时;或当技术栈中已存在成熟的批处理系统时。
- 选择Kappa:当业务以实时分析为主导,系统需要极致简化,且团队擅长流处理技术时;或当数据重计算需求不频繁时。
实践中,也出现了混合架构,即在Kappa基础上,为特定场景引入批处理优化,或利用流批一体的引擎(如Apache Flink,其Table API/SQL在统一API下同时支持流处理和批处理)来模糊两者的界限,这正成为未来的重要趋势。
Lambda与Kappa架构为企业数据仓库的构建提供了清晰的蓝图。而云原生时代丰富的数据处理与存储支持服务,使得企业能够更专注于业务逻辑,而非底层基础设施的复杂性,从而更灵活、高效地构建适应自身需求的数据处理系统。
如若转载,请注明出处:http://www.shuduyouxi.com/product/61.html
更新时间:2026-06-19 13:15:27