超大规模时空数据的分布式存储与应用 构建高效数据处理与存储支持服务体系
随着物联网、智慧城市、自动驾驶及遥感观测等技术的飞速发展,全球范围内时空数据的规模正以前所未有的速度增长。这类数据通常包含时间戳、地理位置及丰富的属性信息,呈现出典型的“4V”特征——体量巨大、类型多样、产生速度快且价值密度不均。如何高效、可靠地存储并应用这些超大规模时空数据,已成为驱动众多领域创新的核心挑战。分布式存储与配套的数据处理支持服务,正成为应对这一挑战的关键技术路径。
一、 超大规模时空数据的存储挑战与分布式解决方案
超大规模时空数据对存储系统提出了严苛要求:首先是海量容量与高可扩展性,数据量常达PB甚至EB级,且持续快速增长,存储系统需能在线平滑扩展。其次是高性能,需支持高并发写入与复杂时空范围查询。再次是高可靠性与高可用性,数据价值高且不可再生,系统必须具备极强的容错能力。最后是成本效益,需要在满足性能需求的同时控制总体拥有成本。
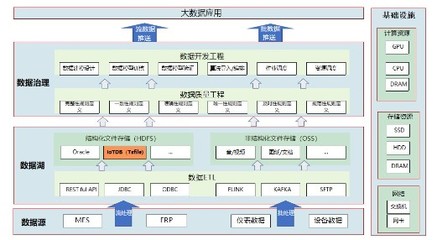
分布式存储系统通过将数据分散存储在大量通用服务器节点上,有效应对了上述挑战。主流的分布式文件系统、对象存储及新型时空数据库采用了分片、多副本、纠删码等技术,实现了容量的近乎线性扩展与数据的冗余保护。针对时空数据的特殊性,存储方案还进行了专门优化,例如:
- 时空索引:设计高效的时空混合索引(如R树变种、GeoHash与时间维结合),加速“某一时间段内、某一地理区域”的查询。
- 数据分区:根据时空局部性原理进行数据分区,将时空上接近的数据存储在物理相邻的节点,减少查询时的网络开销。
- 分层存储:根据数据的热度(访问频率),将热数据置于高性能存储介质(如SSD),冷数据置于高密度低成本介质(如磁带库),实现成本与性能的平衡。
二、 数据处理支持服务:从存储到智能应用的关键桥梁
仅有海量存储能力不足以释放时空数据的价值,必须构建强大的数据处理支持服务层。该服务层向上层应用提供统一、易用、高效的数据访问与计算能力,主要包括:
- 统一元数据管理与服务:建立全局的时空数据目录,对分布式存储中的海量文件或对象进行编目,记录其时空范围、采集源、质量等元数据,并提供高效的发现与检索服务。
- 并行计算框架集成:与Spark、Flink等分布式计算框架深度融合,提供原生的时空数据读取、分区与计算算子,使开发者能够便捷地进行大规模时空数据分析、挖掘与模型训练。
- 流批一体处理引擎:支持实时流式时空数据(如车辆轨迹、传感器读数)的即时接入、处理与存储,并与历史批量数据关联分析,满足实时监控与离线分析融合的场景需求。
- 标准化查询接口与服务:提供RESTful API、SQL扩展(如支持时空函数)或特定领域语言,降低应用开发门槛,让用户无需深入底层存储细节即可进行复杂时空查询与分析。
- 数据治理与安全服务:贯穿数据全生命周期,提供数据质量校验、版本管理、访问控制、审计追踪及合规性保障,确保数据可信、可用、安全。
三、 典型应用场景与未来展望
上述分布式存储与处理支持服务体系已广泛应用于多个领域:在智慧交通中,用于存储和分析全市车辆的实时轨迹数据,实现拥堵研判与信号灯优化;在环境监测中,用于处理全球气象卫星和地面传感器的时空序列数据,进行气候模拟与灾害预警;在数字孪生城市中,作为支撑海量三维模型、物联网感知数据融合与仿真的核心基础设施。
超大规模时空数据的存储与应用技术将持续演进。一方面,存储与计算的融合将更加紧密,存算一体架构有望进一步降低数据搬运开销,提升实时分析效率。另一方面,人工智能的深度介入将成为常态,从智能化的数据分层、索引自动优化到嵌入存储层的AI推理服务,将使整个体系更加自主与智能。随着隐私计算技术的发展,如何在分布式环境下实现时空数据的“可用不可见”安全共享,也将成为重要的研究方向。
构建面向超大规模时空数据的分布式存储与高效数据处理支持服务体系,是一项复杂的系统工程。它不仅是技术的集成,更是对业务需求的深度理解与抽象。通过持续技术创新与生态建设,这一体系必将为人类社会洞察世界规律、优化决策、预测未来提供更为坚实和智慧的数据基石,赋能各行各业的数字化转型与智能化升级。
如若转载,请注明出处:http://www.shuduyouxi.com/product/67.html
更新时间:2026-06-19 05:11:46