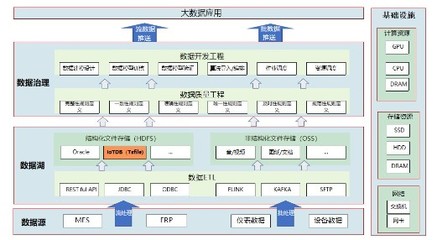
日均数据量千万级场景下,MySQL与TiDB存储方案的落地对比与实践解析
在当今数据驱动的时代,日均数据量达到千万级别已成为许多互联网企业与数字化平台的常态。面对海量数据的实时写入、高效查询与稳定存储,传统单机数据库往往力不从心,分布式架构成为必然选择。本文将以日均数据处理千万级为背景,深入对比两种主流存储方案——经典的关系型数据库MySQL(通常指其集群或分布式解决方案,如MySQL Group Replication、MySQL NDB Cluster或基于中间件分片的架构)与原生分布式数据库TiDB,从数据处理与存储支持服务的核心维度,探讨其落地实践中的优劣与选型建议。
一、 架构设计与扩展性
MySQL(分片架构):
在千万级日增量的场景下,通常采用“分库分表”中间件(如ShardingSphere、MyCAT)或云服务商提供的代理分片方案。其核心思想是将数据水平拆分到多个MySQL实例上,通过应用层或中间件路由规则实现数据的分散存储与访问。
- 优点: 技术生态成熟,有大量成功案例和运维经验可循;对事务(ACID)的支持在单分片内非常完整;基于成熟的MySQL生态,开发和迁移成本相对较低。
- 挑战: 扩展性并非完全弹性。扩容(如增加分片)通常涉及复杂的数据迁移与重分布,可能伴随业务停机或性能抖动;跨分片的分布式事务支持弱,复杂查询(如多表JOIN)需要应用层做大量改造,性能堪忧;运维复杂度高,需要管理多个数据库实例及其之间的数据一致性。
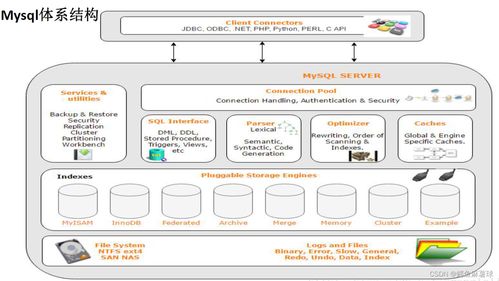
TiDB(原生分布式):
TiDB采用计算与存储分离的云原生架构。计算层(TiDB Server)无状态,负责SQL解析与事务管理;存储层(TiKV)基于Raft协议实现数据的高可用与强一致性,并以Region为单位自动管理数据分片。
- 优点: 具备极强的水平扩展能力。通过简单添加TiKV或TiDB节点即可实现存储容量和计算能力的线性提升,且对业务几乎透明,无需手动分片。原生支持分布式强一致性事务(乐观锁模型为主),跨节点的复杂查询由TiDB层自动优化。
- 挑战: 作为较新的数据库,其周边生态和深度运维经验相较于MySQL略显不足;在极高并发、纯点查(如根据主键查询)的场景下,可能因RPC开销略逊于单分片MySQL;对硬件资源(特别是SSD和网络)要求较高。
二、 数据处理能力
数据写入:
MySQL分片: 写入性能取决于分片规则的设计和单实例的瓶颈。良好的分片键(如用户ID)能实现写入负载的均匀分布。但热点数据(如全局流水号)可能造成单个分片压力过大。
TiDB: 写入由PD(Placement Driver)组件调度,自动均衡到各个TiKV节点。其底层存储引擎TiKV采用LSM-Tree,对顺序写入非常友好,能轻松应对千万级的日增量。自动负载均衡机制能有效规避热点问题。
复杂查询与数据分析:
MySQL分片: 是此类场景的最大痛点。涉及多个分片的查询(如全表扫描、多表关联)需要中间件合并结果,效率低下,通常需要借助额外的OLAP系统(如ClickHouse)或大数据平台。
TiDB: 凭借其分布式SQL引擎,能够将复杂查询下推到存储节点并行执行,并通过MPP(大规模并行处理)架构显著提升分析型查询的性能。配合其生态中的列存引擎TiFlash,可实现HTAP(混合事务/分析处理),一份数据同时支持高并发事务和实时分析,简化技术栈。
三、 存储支持与服务(高可用、运维、生态)
高可用与容灾:
MySQL分片: 高可用依赖于每个MySQL实例自身的主从复制(如半同步复制)或组复制(Group Replication),并结合VIP或代理切换。跨机房容灾方案复杂,且数据一致性保障难度大。
TiDB: 高可用是内置的。TiKV通过Raft协议的多副本机制,确保少数副本故障时数据不丢失、服务不间断。整个集群可轻松实现跨可用区部署,具备金融级的数据强一致性和高可用性。
运维复杂度:
MySQL分片: 需要管理多个独立的数据库集群,监控、备份、升级、扩缩容都是巨大的挑战,对DBA团队要求极高。
TiDB: 提供了完善的运维管理平台(TiDB Dashboard)和云管服务(如TiDB Cloud),集成了监控、告警、慢查询分析、热力图等多种功能,极大降低了分布式数据库的运维门槛。但其分布式特性也意味着需要学习新的知识体系。
生态兼容性:
MySQL分片: 几乎100%兼容MySQL协议和语法,现有基于MySQL的应用可以平滑迁移(但需适应分片规则)。
TiDB: 高度兼容MySQL 5.7协议和生态,绝大多数MySQL驱动、ORM框架(如MyBatis, Hibernate)、管理工具(如Navicat)可直接使用,迁移成本低。这是其得以快速推广的关键优势。
四、 落地选型建议
- 优先考虑MySQL分片方案: 当业务模型相对简单,数据增长可预测,且团队拥有深厚的MySQL运维经验;初期投入预算有限,业务对跨分片复杂查询需求极少;强依赖于MySQL特定功能或第三方工具。
- 优先考虑TiDB方案: 当业务处于快速增长期,数据量和并发量预期会大幅提升,需要弹性扩展能力;业务逻辑复杂,涉及大量关联查询或逐渐有实时数据分析需求(HTAP场景);追求更高的可用性标准(如RTO/RPO要求严格)并希望降低运维复杂度;团队希望拥抱云原生分布式架构,为未来技术演进做准备。
****
面对日均千万级的数据处理与存储,MySQL分片方案更像是一场精心编排的“手工艺术”,在可控范围内表现出色,但天花板明显且运维负担重。而TiDB则代表了一种“工业化”的解决方案,通过原生分布式架构提供近乎无限的弹性扩展、内置的高可用以及简化的运维体验,更适合应对未来不确定性的业务增长和海量数据挑战。最终的选型,需紧密结合业务现状、技术团队能力和长远发展规划,进行综合权衡。
如若转载,请注明出处:http://www.shuduyouxi.com/product/62.html
更新时间:2026-06-19 23:49:14