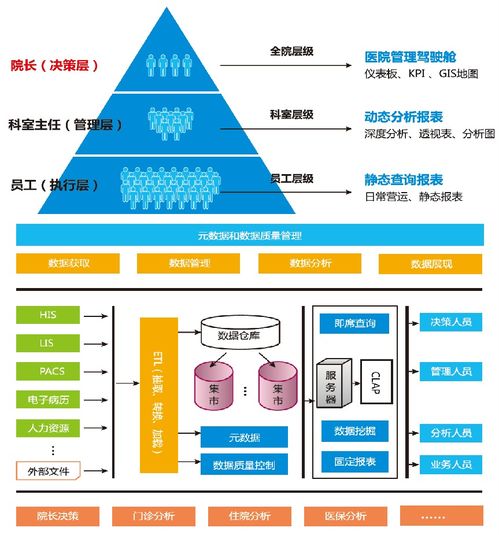
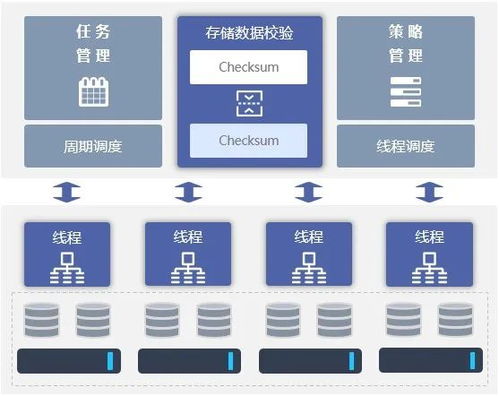
Apache Flink 在实时金融数据湖中的应用 数据处理与存储支持服务

随着金融行业对实时数据处理需求的日益增长,Apache Flink 作为一款高性能的流处理框架,正逐渐成为构建实时金融数据湖的关键技术。Flink 的强大功能不仅体现在高效的数据处理能力上,还在于其对数据存储的灵活支持,为金融机构提供了端到端的实时数据解决方案。
一、Flink 在实时金融数据湖中的数据处理优势
Apache Flink 提供了低延迟、高吞吐的流处理能力,这对于金融场景中的实时交易监控、欺诈检测和风险分析至关重要。例如,通过 Flink 的窗口操作和状态管理,可以实时聚合交易数据,识别异常模式,并在毫秒级别内发出警报。Flink 的事件时间处理机制确保了数据在乱序到达时的准确性,这对于金融时间序列分析极为重要。Flink 与 Apache Kafka 等消息队列的集成,使得数据可以无缝地从源头流入数据湖,并进行实时转换和丰富。
二、Flink 对金融数据湖存储的支持服务
在数据存储方面,Flink 能够与多种存储系统集成,如 Apache Hadoop HDFS、Amazon S3 或 Apache Iceberg,以构建可扩展的金融数据湖。通过 Flink 的 Connector 机制,数据可以实时写入这些存储层,并支持 ACID 事务,确保数据一致性。例如,金融机构可以使用 Flink 将实时交易数据流式写入数据湖中,并通过 Iceberg 表格式实现高效的查询和版本管理。这不仅提升了数据的可用性,还支持历史数据回溯和合规性审计。
三、实际应用案例与未来展望
在实际应用中,许多金融机构已利用 Flink 构建实时数据湖,用于处理高频交易数据、客户行为分析和监管报告。例如,一家银行可能部署 Flink 管道来实时处理市场数据流,并将结果存储到数据湖中,供下游的风险模型和 BI 工具使用。随着 Flink 在容错性和资源管理方面的持续优化,它将在金融数据湖生态中扮演更核心的角色,推动实时智能决策的发展。
Apache Flink 通过其高效的数据处理能力和灵活的存储集成,为实时金融数据湖提供了强有力的支持服务。它不仅加速了数据从产生到洞察的流程,还帮助金融机构应对复杂的数据挑战,实现业务创新和风险控制。
如若转载,请注明出处:http://www.shuduyouxi.com/product/12.html
更新时间:2026-06-19 13:50:04